1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import numpy as np
data_22, labels_22 = load_digits(return_X_y=True)
(n_samples, n_features), n_digits_22 = data_22.shape, np.unique(labels_22).size
reduced_data_22 = PCA(n_components=2).fit_transform(data_22)
kmeans_22 = KMeans(init="k-means++", n_clusters=n_digits_22, n_init=4)
kmeans_22.fit(reduced_data_22)
h = 0.02
x_min, x_max = reduced_data_22[:, 0].min() - 1, reduced_data_22[:, 0].max() + 1
y_min, y_max = reduced_data_22[:, 1].min() - 1, reduced_data_22[:, 1].max() + 1
xx_22, yy_22 = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = kmeans_22.predict(np.c_[xx_22.ravel(), yy_22.ravel()])
Z = Z.reshape(xx_22.shape)
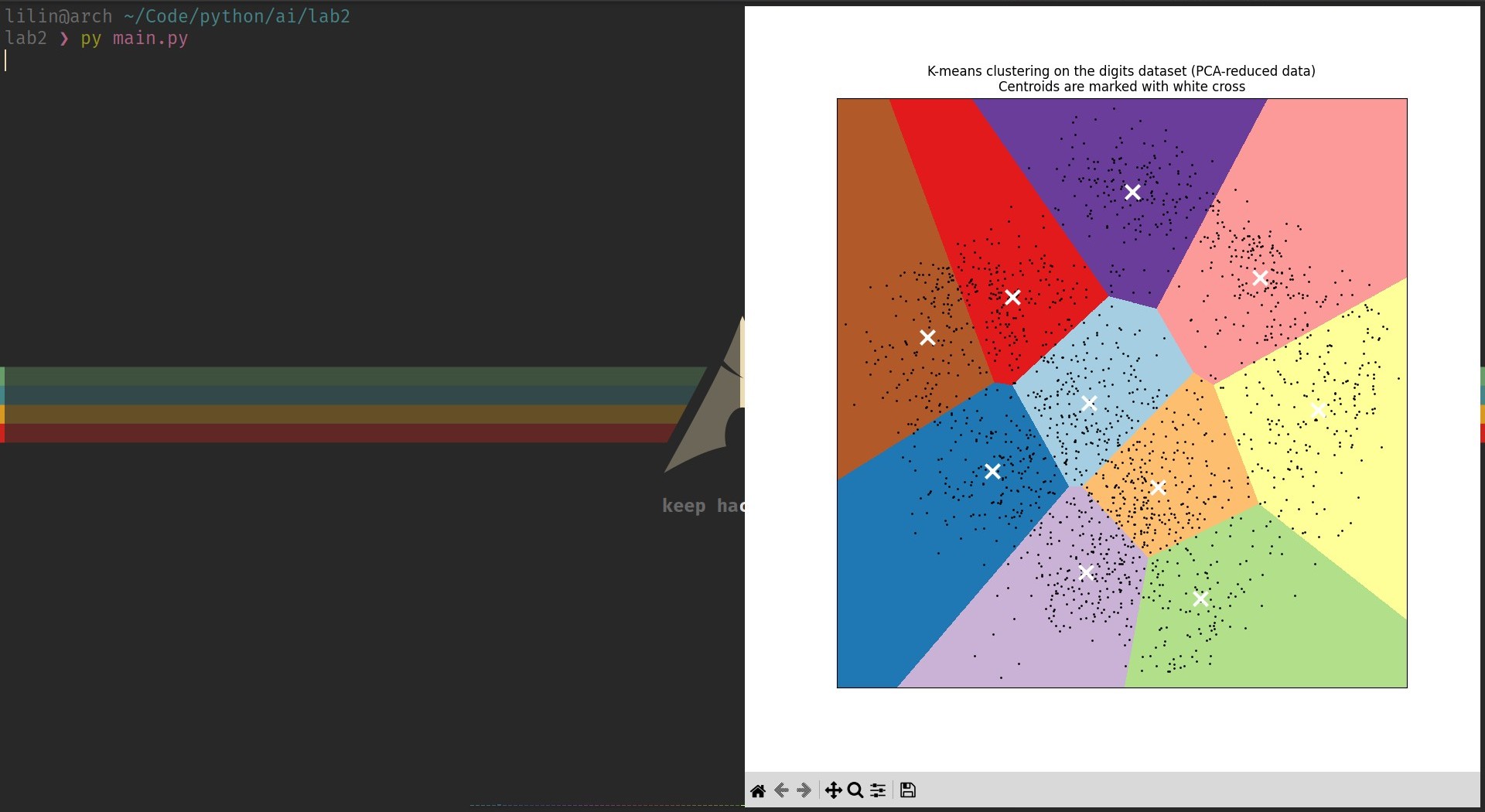
plt.figure(1)
plt.clf()
plt.imshow(Z,
interpolation="nearest",
extent=(xx_22.min(),
xx_22.max(),
yy_22.min(),
yy_22.max()),
cmap=plt.cm.Paired,
aspect="auto",
origin="lower",)
plt.plot(reduced_data_22[:, 0], reduced_data_22[:, 1], "k.", markersize=2)
centroids = kmeans_22.cluster_centers_
plt.scatter(centroids[:, 0],
centroids[:, 1],
marker="x",
s=169,
linewidths=3,
color="w",
zorder=10)
plt.title(
"K-means clustering on the digits dataset (PCA-reduced data)\n"
"Centroids are marked with white cross"
)
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()
|